

Cuanto antes, mejor: el SEO aún tiene mala prensa entre redactores que lo consideran una especie de anticorrección de estilo para extirpar el alma de su texto y ofrecerla en sacrificio a Google.
Esta tirantez proviene de viejos equívocos que han perdurado desde los días en que la densidad de palabras clave era ley. Cada texto se posicionaba para una palabra clave que debías meter con calzador hasta cumplir con unos supuestos porcentajes óptimos sobre el total de palabras, según fórmulas empíricas nunca confirmadas por Google.
Este enfoque ya era inadecuado en 2010, porque ni siquiera consideraba la prominencia de una palabra, es decir, su peso relativo dependiendo de la posición donde aparece, que es mayor si se coloca en lugares como el titular o la entradilla del artículo. Se puede comprobar a simple vista la discrepancia entre densidad y prominencia de los términos de un texto con SeoQuake, una extensión gratuita para el navegador.
De las cadenas a las cosas
La evolución de Google ha obligado al SEO a responder con ingeniería inversa más semántica y menos literal. De considerar palabras clave (cadenas de texto) , la gran G pasó a entender los sinónimos, y a partir de la actualización Hummingbird de 2012 puede identificar los temas para los que es relevante un texto. Ya no hablamos de palabras clave, sino de entidades: cosas (nombres, lugares, personas…) que Google espera que aparezcan en un artículo sobre una temática determinada, que aportan un contexto semántico al contenido, y que además se pueden relacionar con otras entidades.
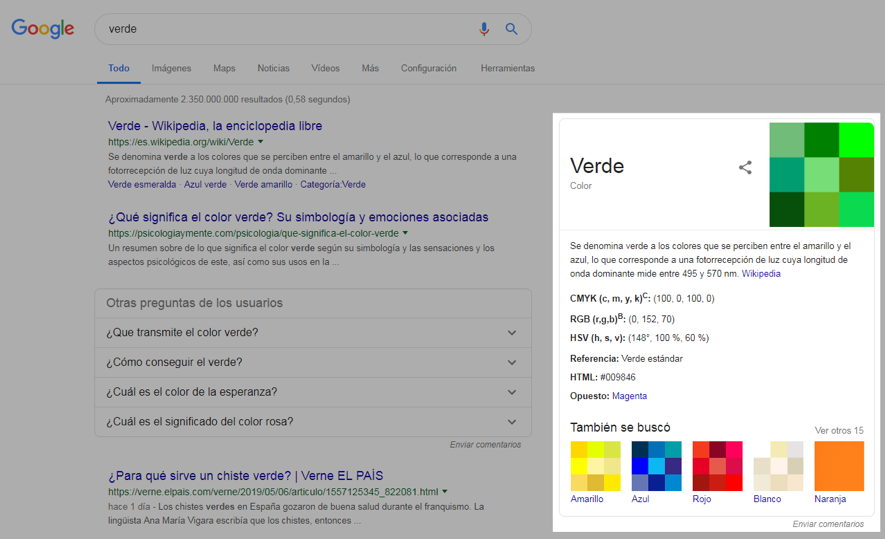
Puedes ver a las entidades en acción cada vez que haces una búsqueda y junto a los resultados aparece esa caja que reúne información general alrededor de tu consulta llamada Knowledge Graph. Este Gráfico de Conocimiento aparece en búsquedas de celebridades, libros, películas, series, recetas… y en palabras muy genéricas: por ejemplo, verde. El algoritmo detecta una entidad (color) con un valor (verde) y la relaciona tanto con otros valores de esa entidad color (amarillo, azul, rojo…) como con otras entidades afines (RGB, CMYK…) que aparecen asociadas con frecuencia en los resultados junto a la entidad color, para componer finalmente el Knowledge Graph.
La frágil coexistencia pacífica con el buscador
En los proyectos de marketing de contenidos de la agencia elaboramos textos, infografías, videos o podcasts para las personas, pero sin dar la espalda a Google.
Se trata de una receta sencilla de formular, pero que reposa en un equilibrio inestable que vemos sucumbir a menudo ante presiones externas en el sector de la comunicación. Sin entrar en el mundillo del SEO black hat, es llamativa la competencia entre redacciones volcadas en agradar a Google por hacerse con el gran pastel del tráfico orgánico del año: la Lotería de Navidad. Demasiado tentador cuando la sostenibilidad de tu medio depende de captar tráfico para monetizarlo vía publicidad o afiliación. Por eso el evento se prepara semanas antes del sorteo, con periodistas dedicados a elaborar piezas de contenido sobre la lotería (esa persona que perdió el décimo, cómo administrar un premio…) que no se escriben para ningún lector, sino para ocupar posiciones en las SERPS (los resultados de Google), y que a menudo ni siquiera pasarán por la portada.
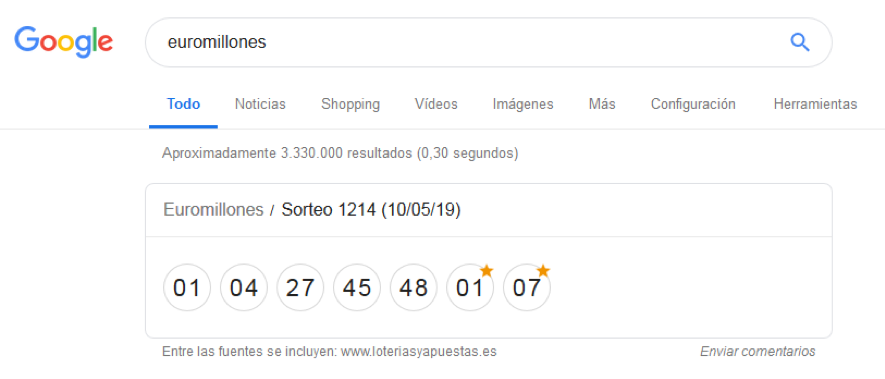
Esta práctica puede tener los días contados. Google cada vez interpreta mejor las intenciones de búsqueda de los usuarios, y cuando consultamos algo sencillo, como un dato concreto (las denominadas consultas Know Simple) el buscador ofrece cada vez más una respuesta directa sin necesidad de salir de la página de resultados (consultas no-click). El buscador extrae (ejem) información de páginas que ya tiene indexadas, como la web oficial de loterías, y la muestra en sus propias cajas de resultados enriquecidos. En 2018 estas búsquedas sin click superaron en Europa el 54% del total. Si los resultados de los sorteos semanales ya se pueden consultar directamente en el buscador, es cuestión de tiempo que Google decida ahorrar al usuario un click también en Navidad.
El otro extremo de la balanza, escribir para el lector sin mirar de reojo a Google, puede ser igual de estéril. Parte del trabajo en la agencia consiste en hacer la auditoría SEO preliminar de otros blogs corporativos. A veces encontramos clientes que llevan tiempo publicando artículos relevantes para su público objetivo, pero que no traccionan en Google porque el buscador no capta las señales de esa relevancia. Tal vez no han considerado el SEO en la estrategia de contenidos y con el tiempo han ido apareciendo problemas de canibalización, con varios artículos que compiten internamente por la misma palabra clave. O incluso puede haber problemas de SEO técnico ajenos al redactor, como una mala implementación del fichero robots.txt que impide al robot de Google acceder a partes del blog (sí, estas cosas pasan).
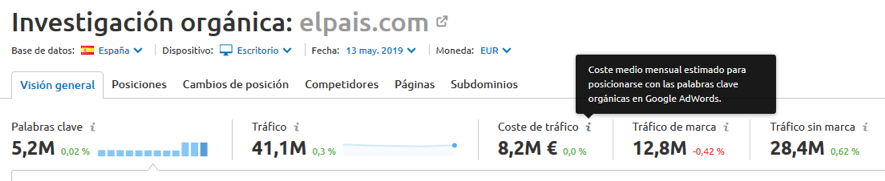
Con los artículos cayendo a plomo en las SERPS como Hans Gruber al final de La jungla de cristal, la dirección de comunicación puede plantearse pulsar el botón del pánico de Google Ads o publicidad en redes sociales, pero no es una alternativa sostenible a medio plazo. El tráfico de pago es habitualmente más caro que el orgánico, como podemos comprobar si utilizamos SEMRush para obtener una hipótesis de la inversión en publicidad de Google necesaria para sustituir las actuales visitas orgánicas a cualquier sitio web por visitas de pago.
¿Te imaginas cuánto tendría que pagar un gran medio como elpais.com para comprar todo su tráfico mensual?
Si creas contenido de valor, ya haces SEO (y no te habías enterado)
La aspiración final de Google es ofrecer la respuesta más adecuada a cualquier consulta que se le haga. En 2016 desplegó Rank Brain, un algoritmo que utiliza Machine Learning para anticipar las intenciones de búsqueda de los usuarios a partir del análisis de enormes cantidades de datos reales de navegación.
Cuando hacemos una consulta, Google también tiene en cuenta como factor de posicionamiento el histórico de experiencia de usuario que han ofrecido esos resultados. Si los datos de navegación de un resultado son peores que la media de resultados de esa SERP porque el usuario sale inmediatamente de la página o apenas pasa allí unos segundos, el algoritmo lo interpreta a la larga como señal de que esa página no ofrece la mejor experiencia de usuario o no es relevante para esa búsqueda, y puede hacer que pierda posiciones. Algunas señales negativas que considera Rank Brain son:
- Una alta tasa de rebote: entrar y salir de una página sin interactuar o navegar.
- Un elevado porcentaje pogo-sticking: entrar en una página desde los resultados de Google, volver inmediatamente al buscador pulsando el botón atrás del navegador, y pulsar en otro resultado.
- Un bajo Dwell time: el tiempo de permanencia en la página antes de volver al buscador.
¿Cómo prevenir la aparición de estas señales? Entre otras cosas, con un contenido que aporte valor, tal como insiste el mantra de Google. Un contenido que retenga al usuario en la página de aterrizaje, le ofrezca una respuesta a la consulta que le ha llevado hasta allí y le anime a seguir navegando por la página web, suscribirse a una newsletter, descargar un white paper… tal vez hasta hacernos merecedores de un enlace.
La convergencia de SEO y redacción periodística
En la agencia no creemos que los redactores deban renunciar a su estilo natural de escribir para cumplir con las directrices de calidad de Google. A fin de cuentas, crear contenido único, original y que aporte valor ya es nuestro negocio. Pero además, hay prácticas cotidianas de redacción que se ajustan muy bien a las necesidades del SEO on page, por ejemplo:
- La clásica estructura de pirámide invertida, con el contenido más importante al comienzo del texto, es perfecta para situar de forma natural algunas palabras clave en esa parte superior del artículo donde son más prominentes. Y si además escribimos una buena entradilla capaz de retener la atención del lector para reducir la tasa de rebote, estaremos enviando señales positivas a Google.
- Un texto redactado con criterios SEO incluye la palabra clave principal en el título, dentro de la etiqueta H1, y las palabras relacionadas en sucesivas etiquetas H2 y tal vez H3. Esta jerarquía de etiquetas encaja como un guante con la habitual división del texto periodístico en secciones que faciliten la lectura. Si ya tenemos titulares, subtítulos, ladillos… ¿por qué no aprovechar para supervitaminarlos?
- La etiqueta description es lo que denominamos una metaetiqueta. Está dentro del código HTML de la página pero no se ve en pantalla, sino en las SERPS de Google, debajo del título y la URL de cada resultado. Es el gran olvidado del copy SEO porque no es un factor directo de posicionamiento, pero no deja de ser un recurso a nuestra disposición para conseguir más clicks a nuestro resultado. Ese enlace es el equivalente a la llamada en portada a artículos interiores. Un redactor puede aprovechar su habilidad para escribir un texto de 155 caracteres que aumente el CTR de ese resultado.
- El pie de foto, que en periodismo aporta contexto a una imagen, en el SEO hace eso y algo más. En redacción de contenido web disponemos también del equivalente del pie de foto visible para el lector, pero además podemos -y debemos- incluir en la foto otra metaetiqueta descriptiva llamada ALT de cortesía para la araña del buscador. Cuidar el SEO de las imágenes no suele ser la prioridad cuando los plazos son ajustados, pero nos perdemos una oportunidad adicional de visibilidad en los resultados de Google Images, un auténtico tapado que según un estudio de SparkToro era en 2018 el segundo buscador más utilizado en EEUU.
Asistentes de contenido, ¡reuníos!
El SEO no tiene sentido como una capa adicional dentro de una cadena de montaje de textos, sino como la incorporación de metodologías transversales en el trabajo de una agencia o una redacción. Pero, ¿cómo ponerlas en práctica?
Ya existen algunas herramientas comerciales que facilitan al autor la incorporación de criterios SEO a los contenidos durante la redacción. Lo primero que hay que dejar claro es que son herramientas auxiliares, no sustituyen al redactor ni sirven para escribir en piloto automático. El software de copywriting SEO ofrece consejos para mejorar la calidad de un artículo por dos vías: afina la orientación de un contenido hacia una palabra clave determinada, y ayuda a encontrar nuevas ideas en forma de sugerencias de palabras relacionadas que podemos haber pasado por alto.
En la sala de máquinas de los asistentes de contenido funciona una métrica de análisis de contenido llamada TF*IDF. En pocas palabras, mide con qué frecuencia aparece un término dentro del total de palabras de un texto (Term Frequency), y luego lo compara y lo compara con el número de documentos que mencionan ese término en un corpus determinado de documentos (Inverse Document Frequency). Como no sería operativo comparar nuestro texto con todos los resultados de Google, las herramientas toman un atajo práctico y analizan el contenido de los 10, 20 o 100 primeros resultados (depende de la herramienta) que a fin de cuentas son nuestros competidores en las SERPS.
El trabajo con estos programas sigue habitualmente los mismos pasos en un proceso iterativo: se les indica la palabra clave principal a la que se orienta el artículo, se introduce el texto a analizar (o la URL si ya está publicado), y se comprueban las sugerencias. Una vez que se ha modificado el texto, se vuelve a analizar.
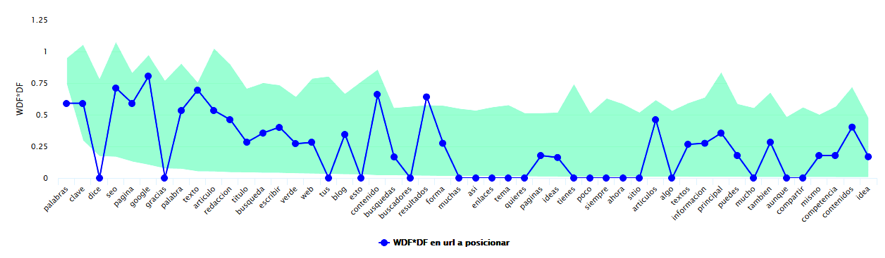
Las sugerencias intentan alinear finalmente dos valores: por un lado, una puntuación de relevancia de cada palabra que empleamos en nuestro artículo relacionada con el término principal, y por otro lado otra puntuación con el peso medio de esas mismas palabras en los artículos que están más arriba en Google. Por ejemplo, un análisis de este mismo artículo para la búsqueda redacción seo arroja estos resultados, con la mayoría de keywords relevantes dentro de los márgenes que marca la franja verde.
Una de las primeras herramientas de este tipo en aparecer fue la opción TF*IDF incorporada a la suite Ryte. Otras soluciones más adaptadas a la optimización de contenidos en equipos de redacción o agencias son Seolyze o Similar Content, que ofrecen sugerencias en tiempo real mientras se escribe el texto en su editor.
La alternativa made in Spain es el módulo WDF*DF de DinoRank, más asequible para un redactor freelance y única con el interfaz y la documentación totalmente traducidos a nuestro idioma. El recién llegado a este mercado es el Asistente de Contenido de Sistrix, actualmente en fase beta (en mayo 2019), que añade sugerencias para responder a las intenciones de búsqueda más probables e intentar aparecer en los resultados enriquecidos.
Una interesante opción freemium para terminar es Seobility, con tres análisis diarios gratuitos que te permiten averiguar si el análisis TF*IDF puede aportar mejoras a tu forma de trabajar.
Si estás impulsando una estrategia de contenidos y crees que tu trabajo no recibe la visibilidad que merece, tal vez desde agencia Comma podemos echarte una mano.

